Updated
—
7 min read
My Flowchart for Coding with LLMs Effectively
Simple flowchart capturing the intuition around coding with LLMs
When working with LLMs, my goal is to optimize human reviewability.
Every piece of generated code should pass through genuine human understanding before it ships.
Because the moment you're working in a production codebase with real users, real invariants, and real consequences, the bottleneck is verification, not code generation.
I've made the naive mistake of prompting a code assistant to do a task a bit too large.
It completes it. Maybe everything even looks good on the surface.
But now you have dozens of files and thousands of LOC to review. Because how do you know it did it right? That it didn't take shortcuts, introduce footguns, or break your conventions?
And reviewing code is cognitively hard. Often much harder than writing code.
Don't get me wrong. Coding assistants are impressive. The LLM could do the 1000-line refactor, but that's irrelevant to me if I can't confidently and efficiently verify the result.
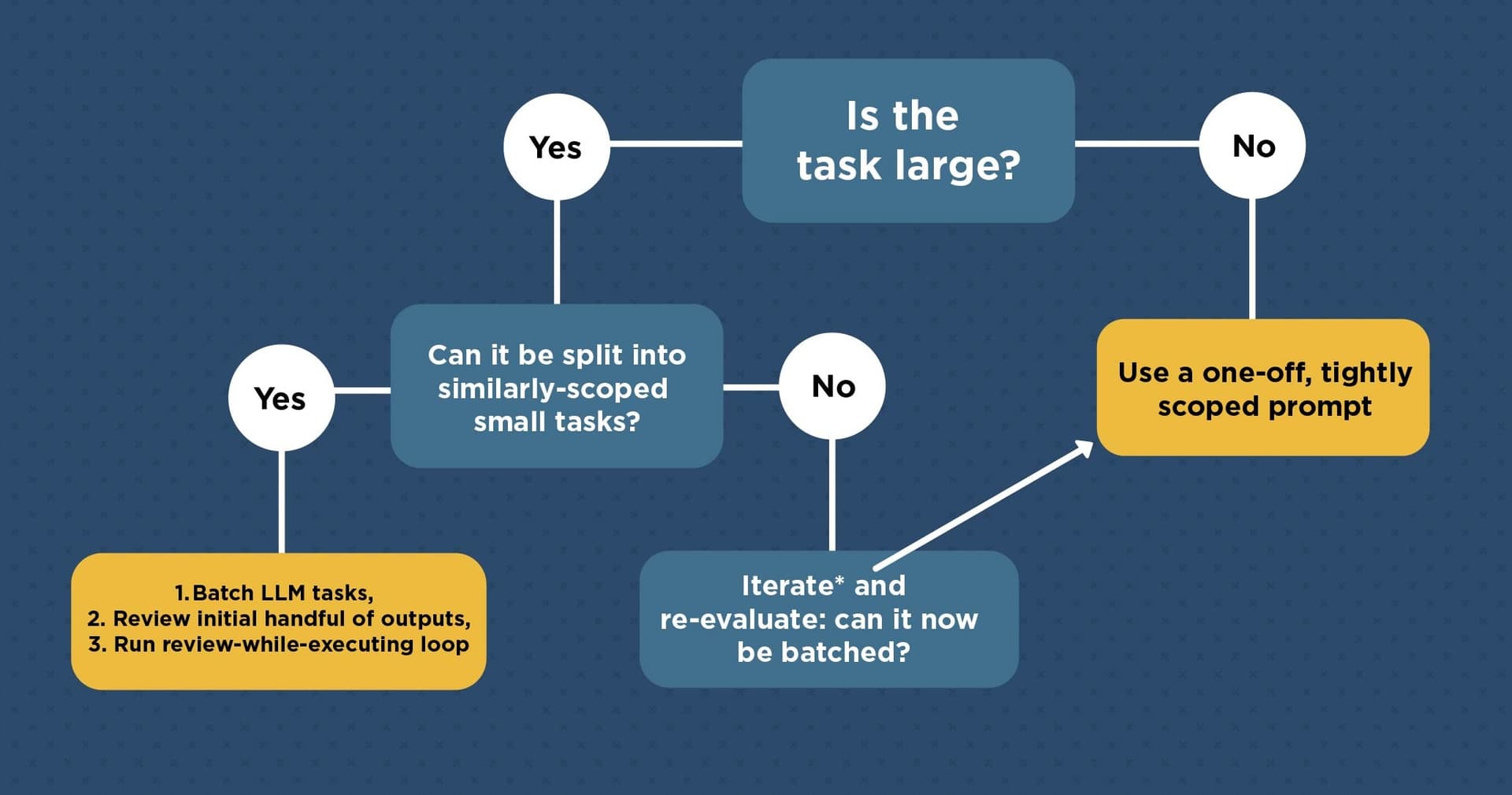
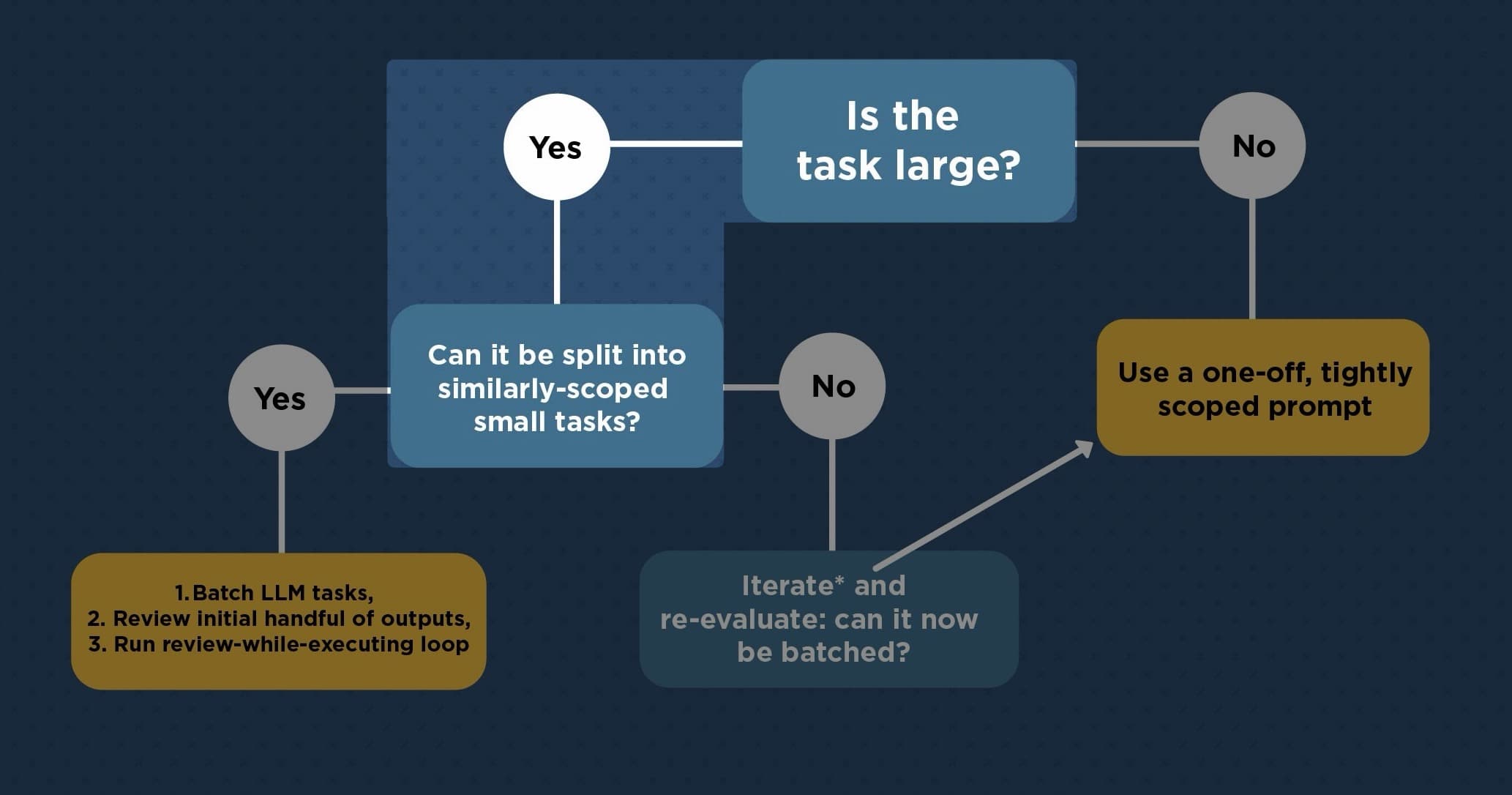
My personal framework for working with LLMs while coding can be distilled into a flow chart:
How to use coding LLMs, a decision tree:
Is this task large? (non-trivial and/or more than a few minutes of human effort)
- No → Single, tightly scoped prompt. Review output. Done.
- Yes → Can you decompose it into similarly-scoped subtasks?
- Yes → Batch to LLM. Enter the calibration → production pipeline (see below).
- No → Iterate incrementally via tight human↔LLM oscillation. Reassess periodically whether the remaining work can now be decomposed into a batch.
Here's each decision tree branch in detail:
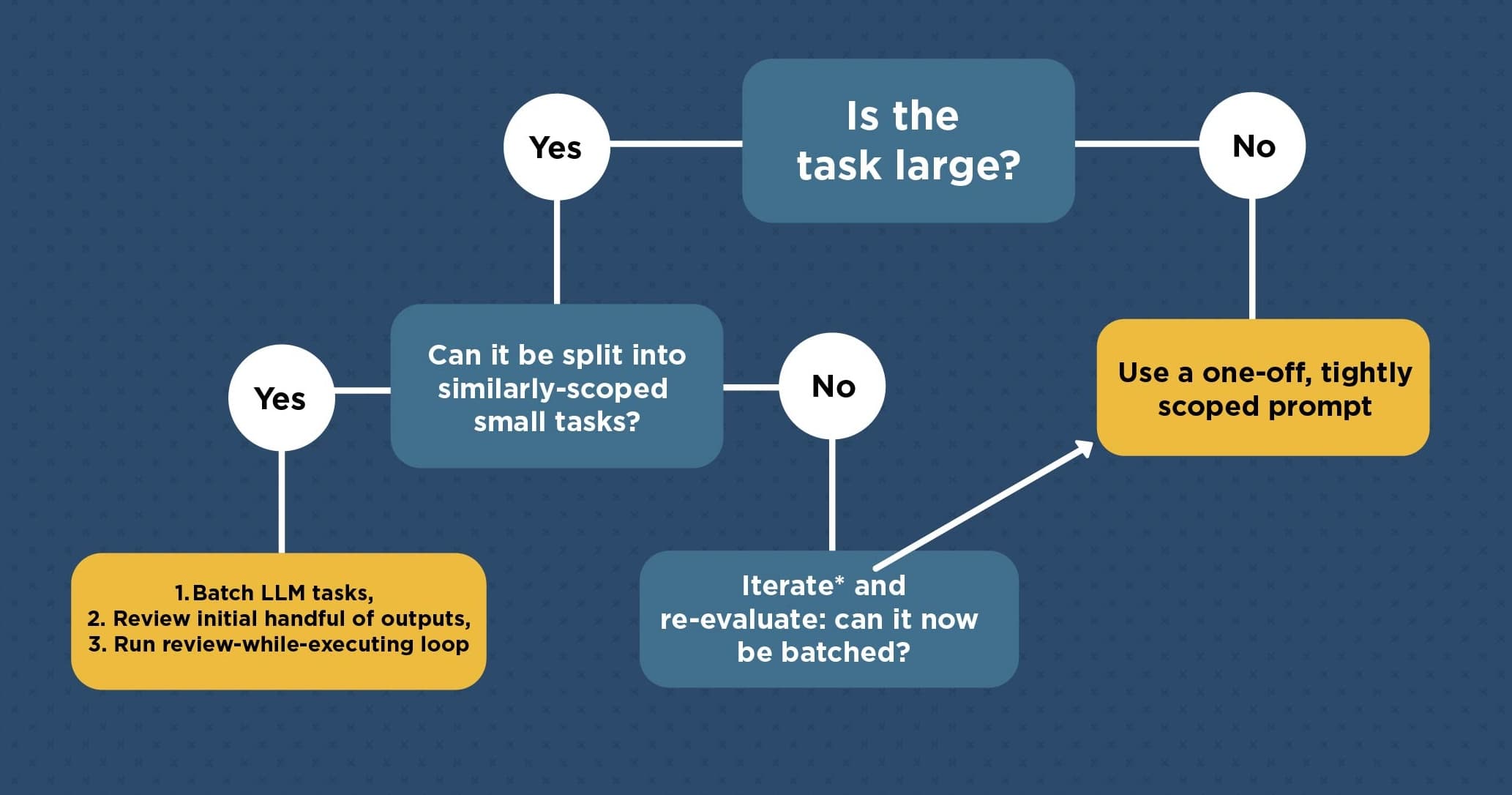
1. "Is this task large?"
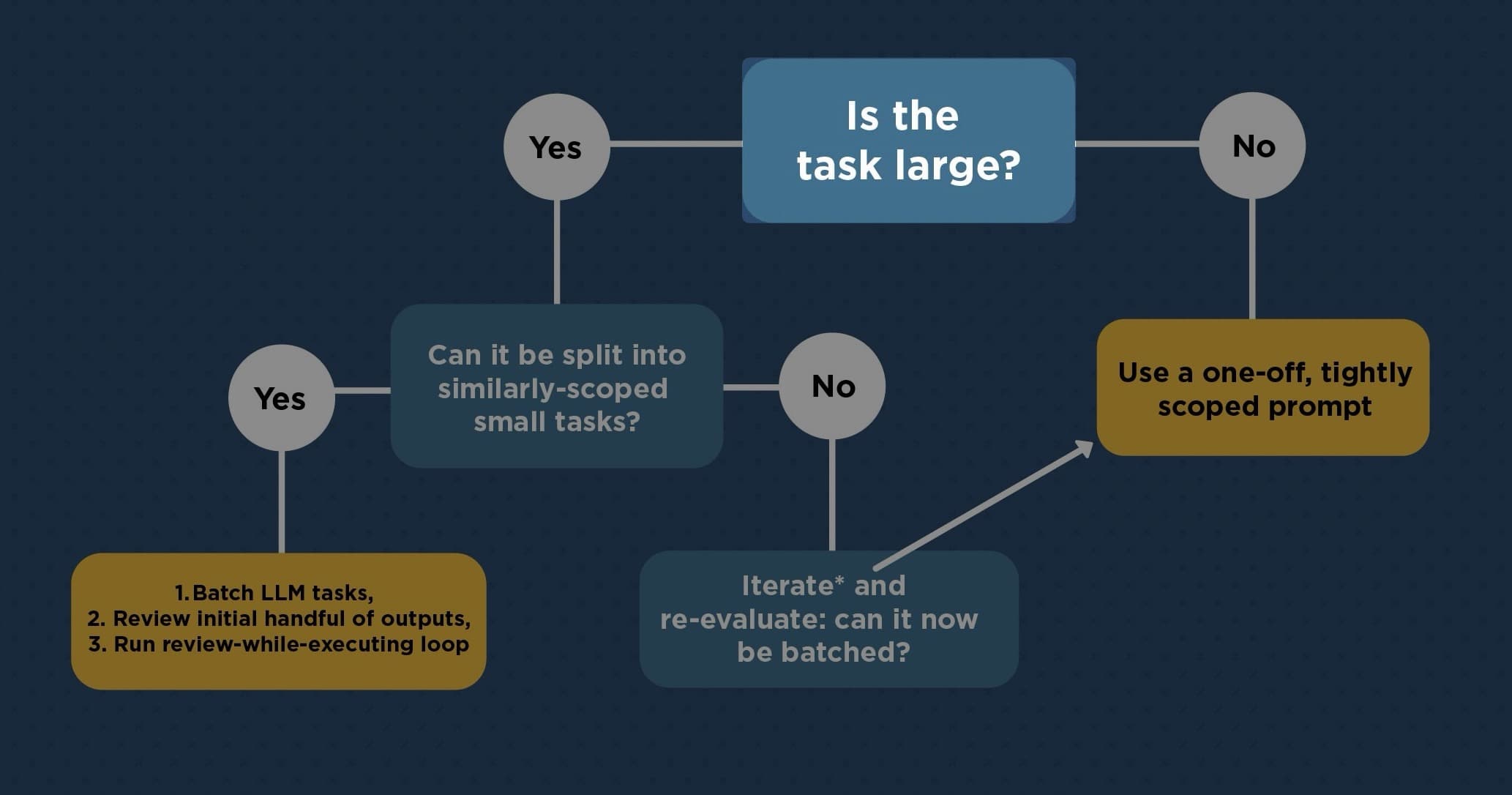
"Large" means you wouldn't trust an LLM output without substantial review effort.
The test is less about absolute size and more about verification cost.
It may be true that the time to review LLM output is less than time it would've taken to code it yourself even for "large" tasks.
But this evaluation also needs to take into account your confidence (or lackthereof) that you've reviewed generated code thoroughly and any re-prompting and re-execution time (plus any subsequent verification).
In practice, the equation isn't as clean as "time to review" vs "time to code". And in many cases, "time to review" can be genuinely greater than the time it would've taken you, not the LLM, to engineer the same thing.
"Large" and "small" here are purposefully ambiguous. In practice, it's mostly intuitive, but often "large" means many interdependencies, unknowns, architecture design choices, etc.
2. Small task → single scoped prompt
Nothing fancy here. Write a clear, tightly scoped prompt, review the output, and move on. Most of my day-to-day LLM usage lives here.
I just want to avoid packing multiple concerns into one prompt just because the LLM could probably handle it.
Again, it's not about kneecapping the LLM, but keeping things verifiable. I know LLMs can do impressive coding. I just also need to be able to review it efficiently.
This is one step above "autocomplete" usage of LLMs. Easily scoped. Easily verifiable. Easily repeatable.
Since it takes a few seconds or minutes, there's also little "waiting gap" (another interesting quirk of working with LLMs is the "downtime" between prompting, which this flowchart tries to minimize without context-switching or "Just work on something else bro!").
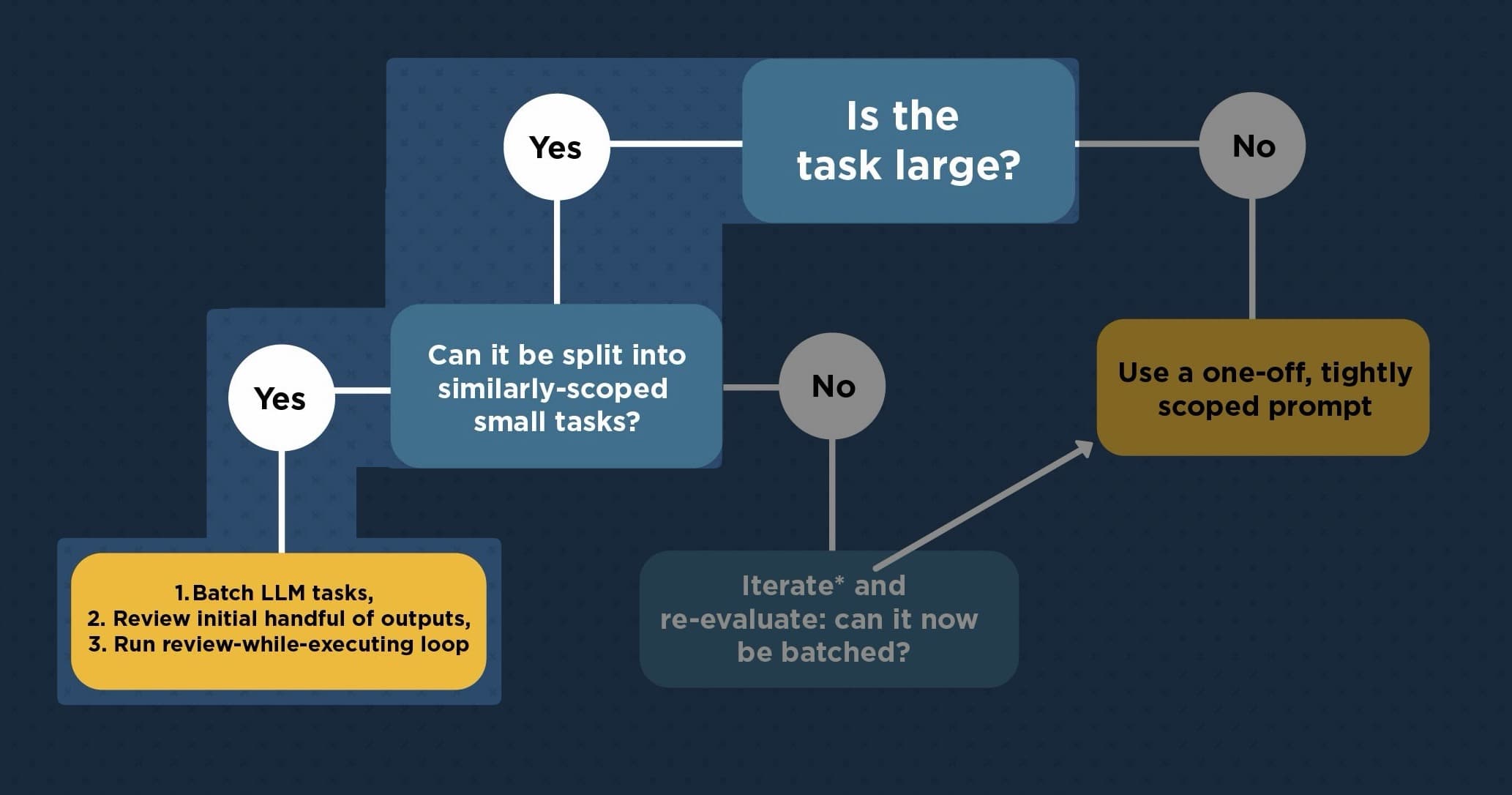
3. Large task → can you decompose into similarly-scoped subtasks?
If the answer is "no," that usually means the task has too many interdependencies or unknowns, which is exactly the kind of work where LLMs are most likely to go off the rails with a large prompt anyway.
So the decomposability test is simultaneously telling you 1.) how verifiable the task output will be and 2.) how likely the LLM is to succeed competently.
Because a large, hard-to-decompose task will be brutal to review the generated code. And these kinds of large, hard-to-decompose are also at the frontier of coding assistant capabilities.
Again, this is mostly intuitive and nothing rigid. I'm just broadly looking for subtasks that share enough structure that reviewing one teaches you what to look for in the rest.
For example:
- Migrating 20 API endpoints to a new pattern
- Adding tests for a set of similar modules
- Updating a repeated code pattern across many files
If the subtasks are all unique in shape, you can't build reusable review intuition, so batching won't help (skip to step 5).
If the subtasks are similar, then you can batch and run a "review-while-execute" loop (step 4).
4. Batchable → calibration → production pipeline
Great, so you can batch a large task into somewhat repeatable subtasks.
Here the challenge becomes one of efficiency. So this has two phases:
Calibration (first N tasks):
Run one subtask at a time. Review output carefully. Adjust the prompt, the context you provide, and your expectations.
Essentially, you're "blocking" on each result.
The goal is to converge on a prompt that reliably produces output you're confident reviewing.
This is identical to step 2, but you're just iterating on the prompt and context, reviewing after each LLM output.
Production (remaining tasks):
Now you kick off subtask N+1, and while it runs, review the output of subtask N.
I like this "review-while-executing" loop because it minimizes the "waiting period" of working with LLMs. Even if your subtasks here grow in size, you don't need to "just work on something else" while you wait. Instead, the LLM execution and human review are tightly coupled, so I'm able to keep context and focus.
And since you've already built a mental model of what "good" looks like, so review is relatively fast.
Individual subtasks can be substantial (5–15+ minutes of LLM work). That's fine because the calibration phase earned you the trust to run them with lighter-touch supervision. And you can always drop back into calibration mode if quality drops.
5. Not batchable → tight human↔LLM oscillation
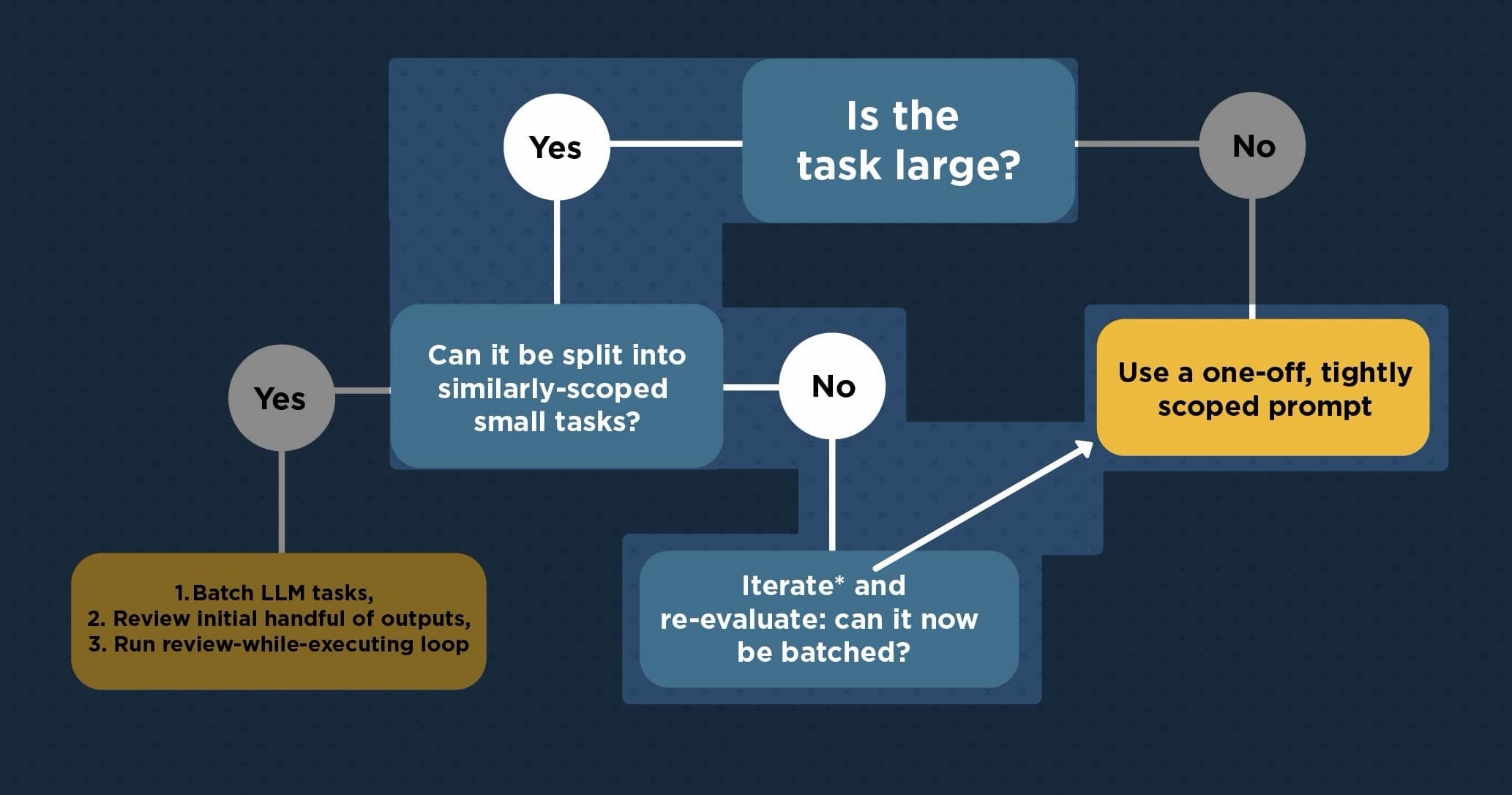
For large tasks that resist decomposition into similar chunks, I want to stay small and incremental.
Use the LLM for scoped, bounded pieces of the work, like generating a function, sketching an approach, refactoring a single section.
Then review, integrate, and prompt again. You're essentially staying in calibration mode permanently, which is fine.
The frequent review checkpoints are the whole point: they keep the verification surface manageable and catch drift early. And as you make progress, you can periodically reassess whether the remaining work has become regular enough to batch.
Where you can't batch, you iterate with one-off prompts, but keep reevaluating whether batching becomes possible. You might start a refactor thinking it's a unique, context-heavy change, but after making some progress you realize "oh, there are actually twelve components that need this same transformation."
Summary
The flow chart isn't mean to be comprehensive or rigid. It's a rough heuristic for how I think about using coding LLMs.
It's rather simple and I don't intend to overcomplicate it, make it a formal "framework," or anything like this.
It really comes down to:
- Optimizing for human reviewability over raw code generation
- Being heavily biased towards scoped/small-scale LLM tasks
- Minimizing "waiting period" gaps (which often result in context switching or distraction)
Let me know what you think! There's lots of different approaches to using LLMs when coding, so I'll be curious how this compares.
Join my newsletter for lessons, experiments, and failures in bootstrapping online businesses.
Sign up if you're curious. I’ll only email you if it's actually good.

Meet the Author
Ryan Chiang
Hello, I'm Ryan. I build things and write about them. This is my blog of my learnings, tutorials, and whatever else I feel like writing about.
What I'm currently building →.